How Brainstore works: architecture for AI observability at scale
Recently I've heard an observation circulating: that AI observability is actually a database problem. This sounds trite, but it's true. The novel workloads that AI products generate and the exciting ways you can use that data mean it's in the database itself that the real problems lie. We realized this the hard way at Braintrust almost two years ago and built a custom database called Brainstore for these reasons.
This may appear to be a lot of work for minimal returns, especially given the open source databases out there and the long history of existing database architecture. But taking a small number of big, concentrated technical bets is the strategy behind the most important products we're building at Braintrust.
Making Brainstore one of our bets has paid off. As we've grown and our product has expanded, Brainstore has only become more important, and the related challenges have grown in complexity. Agent traces in particular are a serious problem for traditional database architectures. Agents are now multi-turn, with complicated tool calls, and the data they generate when operating far exceeds the APM traces we're used to.
So we thought it'd be interesting to explain the why and the how of Brainstore, so others can learn from our process.
What makes AI observability hard
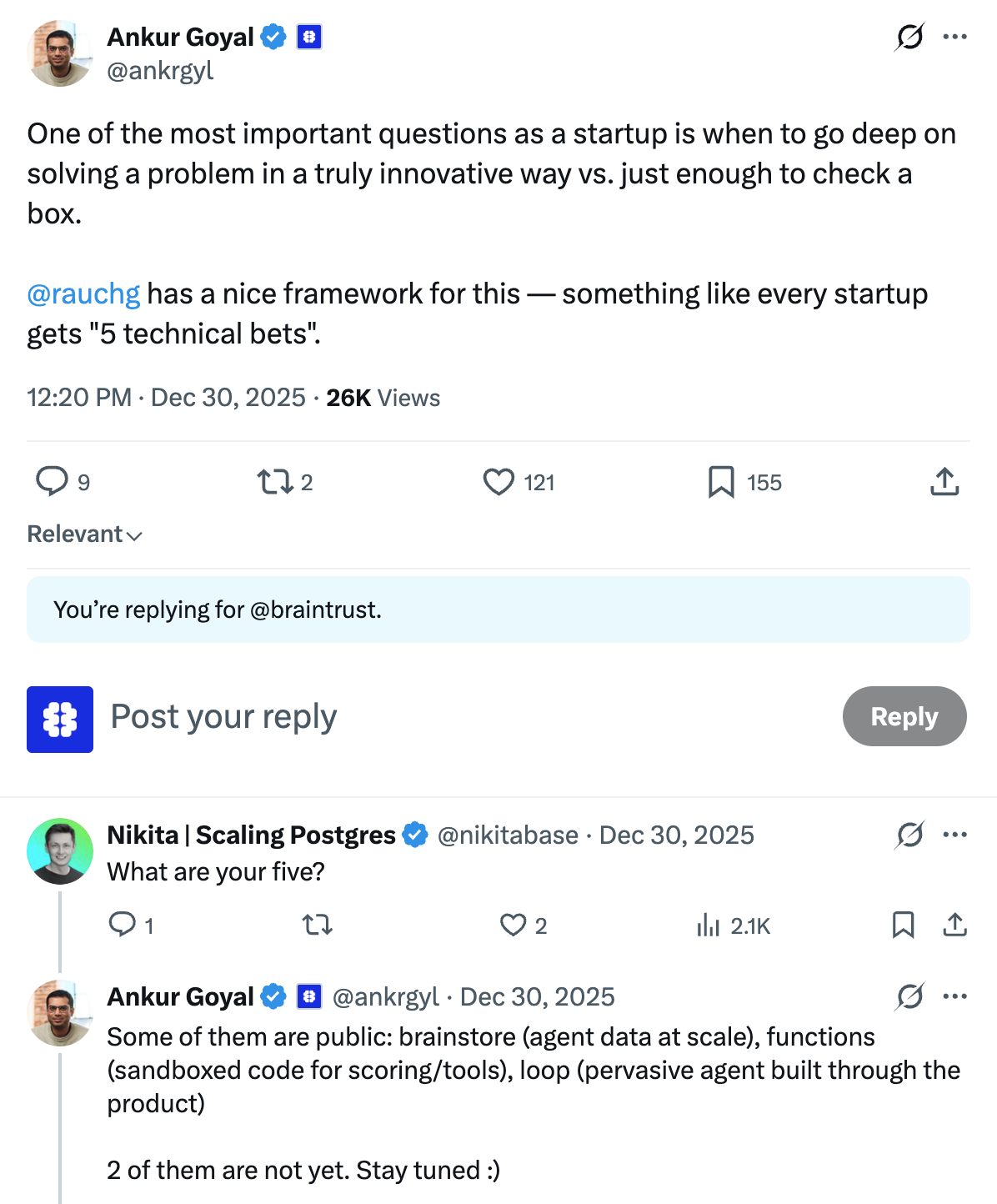
AI observability pushes database systems in ways that look familiar on paper but quickly become extreme in practice. The first pressure is ingest. Production systems can generate on the order of 100,000 spans per second, which means the database has to accept a constant stream of writes without coordination becoming the bottleneck.
The second pressure is payload size. Compared to traditional observability, spans and traces are much larger. They contain entire prompts, responses, intermediate reasoning steps, and tool calls, and can even include entire conversation histories. A typical span can be ~50 KB and a typical trace ~10 MB. At p90, that can jump to spans in the tens of MB and traces that reach tens of GB. In other words, AI traces can be two to three orders of magnitude larger than what many "logs and metrics" stacks were designed for.
The third is that traces run for a very long time (sometimes days) and feedback can come out of order, so you need to be able to update them once they've completed their runs.
Finally, the data itself is often messy. It tends to be semi-structured, with very large fields (1 MB+ is common). Many of those fields are effectively serialized application state. Teams are logging what they need to reproduce a failure or evaluate an agent, not just what they need to debug a single request.
On the read path, the workflow is also bimodal. When investigating an issue or reviewing evaluations, engineers often bounce between deep inspection of a single result and fast iteration across a large set of runs. That creates two simultaneous requirements. Detailed test cases have to load quickly even when they are huge, and broad query and filtering has to feel interactive so exploration and pattern-finding is not painful.
A few operational expectations also tend to be non-negotiable. Traces need to show up immediately after ingest. Data can arrive out of order across long horizons, ranging from hours of agent execution to days of delayed feedback, and partial progress still has to be visible. And because prompts often contain PII, many teams need a self-hosted deployment model. That means stateless services, minimal clustering, and no complex persistent-disk story.
The pre-Brainstore stack (and why it broke down)
Before Brainstore, Braintrust served the product with a three-part stack. An open-source warehouse handled storage and analytics, Postgres provided low-latency reads immediately after ingest, and DuckDB ran in the browser for the last mile of interactive analysis.
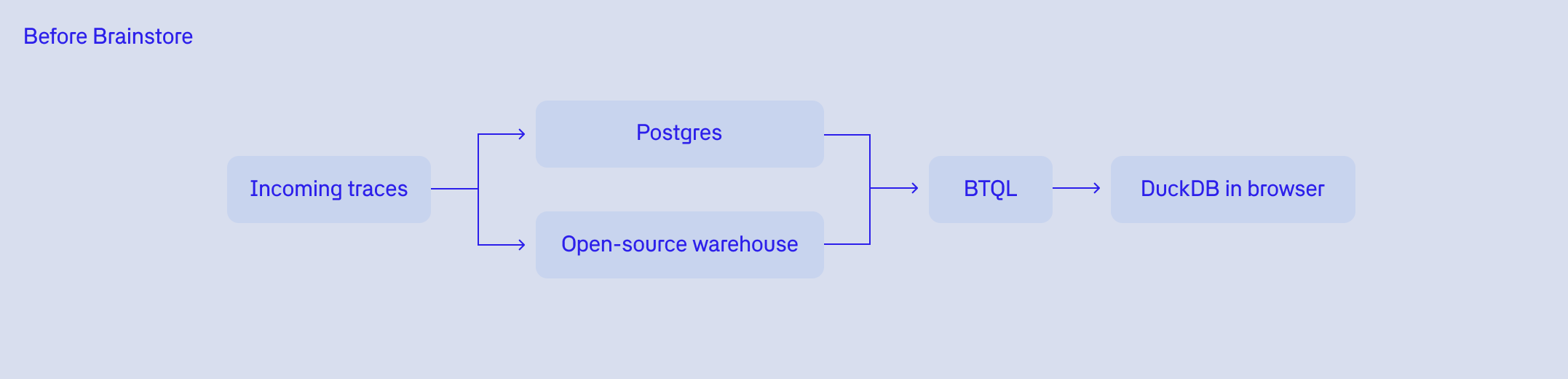
On paper, this looks like a pragmatic decomposition of responsibilities. In practice, it turned into a fragile architecture with failure modes in every direction.
The open-source warehouse could absorb the raw volume, but ingesting updates quickly was difficult. Even with various query workarounds, end-to-end data latency still tended to be measured in minutes.
At the beginning, Postgres did what it does best and provided fast reads right after ingest. But it was not built to handle this mix of scale, query patterns, and write amplification indefinitely. As load increased, it started to struggle on both reads and writes. At times, writes would take minutes, and the database could become unresponsive because GIN index updates simply could not keep pace with ingest.
DuckDB was meant to make the UI fast by moving analysis into the client. But it also became a bottleneck. Correctness issues surfaced, and memory use could spike. A browser consuming gigabytes of RAM to process megabytes of data is not a good experience.
There was also a compounding product tax. The team at Braintrust wanted a unified query syntax (BTQL) for dynamically typed expressions like scores.Factuality < 0.5 or metadata.user_id = '1234'. Translating that language into three separate SQL dialects became increasingly painful and fragile as the language evolved.
Beyond those headline issues, the cracks showed up elsewhere. Full-text search performance was poor, complex queries could return incorrect results, dynamically typed expressions were hard to compile reliably for both Postgres and the open-source warehouse, and the overall system could crash in ways that depended on the developer's hardware.
Rethinking the architecture
After more than a year of trying to work around these limitations, the team concluded that the architecture needed a reset.
Benchmarking pointed to a different approach. Pairing a fast search and indexing engine like Tantivy with object storage for durable scale showed significantly better read performance, while also creating a cleaner separation between ingest, indexing, and query.
Some argue that you should never build your own database. It is time-consuming, difficult, and many open-source alternatives already exist. In the abstract, this is good advice. But Braintrust as a platform cannot deliver the experience customers expect if the database architecture regularly fails.
The question was what Braintrust needed that the existing stack could not deliver.
It needed to support arbitrary queries over traces, including filtering, projection, and grouping over any field or subfield, with fast full-text search and nested lookups.
It needed to support updates to any trace at any time. Customers should be able to add new spans after a parent has completed, and those writes should become visible immediately.
It needed to be easy to operate in environments where data cannot leave the customer's boundary. The deployment model is intentionally simple. It relies on stateless containers and first-party cloud services like object storage, Postgres, and Redis, without requiring customers to run the open-source warehouse, manage persistent disks, or ship private data to Braintrust-managed infrastructure.
The philosophy behind Brainstore's architecture is that making reads and writes simple, fast, and scalable at extreme scale is a product differentiator. Braintrust should feel like it was built for production AI systems, rather than adapted to them, and Brainstore is how that happens.
Architecture goals and strategy
Brainstore's core architecture is driven by three design goals.
First, all data lives on object storage. This gives effectively unbounded scale and strong durability, and it is simpler to operate than systems that depend on local disks for core state. Many commercial stacks only partially use object storage while still relying on persistent disks for metadata, statistics, or consensus. That hybrid approach tends to inherit the operational complexity of both worlds.
Second, each customer's data lives in its own partition. This avoids the "everyone shares one massive table" dynamic that is common in warehouse-based architectures, where performance predictably degrades as the global dataset grows. When querying by customer_id in a partition, less data needs to be scanned, and results can therefore be retrieved much faster.
Third, Brainstore treats semi-structured data as a first-class citizen. Warehouses often handle JSON by shredding it into columns, which can work for shallow and stable schemas. It breaks down when schemas evolve quickly, get deeply nested, or contain large fields.
Brainstore achieves these goals with an architecture structured around a small set of building blocks.
At ingest time, writes land in a write-ahead log, with roughly one file per request. This allows very high write throughput without coordination, aside from transaction ID assignment (handled via Redis).
In the background, the system compacts those writes into segments that are loosely time-ordered, guaranteeing that all spans for the same trace end up in the same segment. Each segment maintains multiple indexes, including a row store, an inverted index, and a column store, so different query patterns can be served efficiently.
Finally, there is a metadata store that tracks the indexing metadata and statistics needed to plan and accelerate queries.
Because reads and writes are separated so cleanly, it can be helpful to frame the system around the following challenges: producing a queryable index as quickly as possible, given a write-ahead log with one file per write request; and planning and executing queries efficiently against that indexed data, getting filters, pruning, and aggregation order right so results are fast and correct.
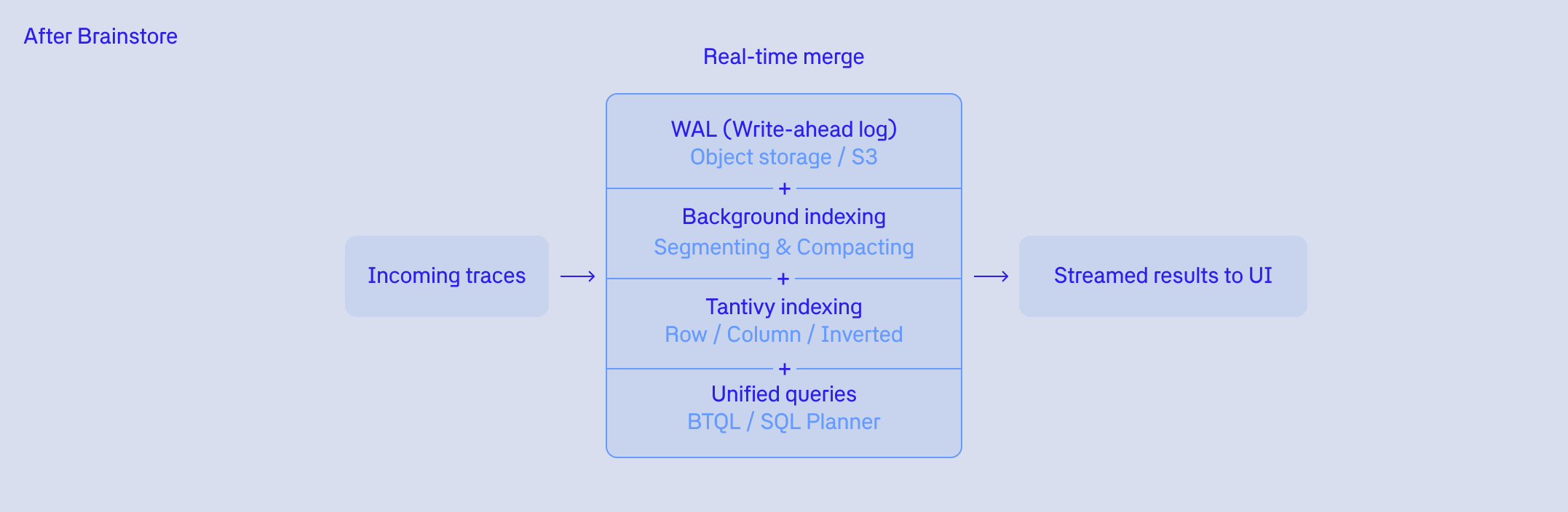
Write path
On the write path, every request appends to a write-ahead log (WAL) on object storage. This ensures high throughput without coordination bottlenecks, and it makes data durable immediately.
From there, Brainstore turns the WAL into an index in two background steps:
Processing: assign new records to a segment (a medium-sized, time-ordered chunk of data), guaranteeing that all spans for a trace land together so trace inspection stays fast.
Compacting: convert processed WAL entries into efficient indexed formats including an inverted index, row store, columnstore, vectors, and bloom filters. We still use the Tantivy-backed index format from earlier versions of Brainstore, but have recently expanded to these other formats as well.
The important design choice is that indexing is asynchronous and continuous. The system is always catching up, producing a steadily improving read-optimized representation of the data.
Read path
On the read path, Brainstore runs an explicit query pipeline: it parses the query (BTQL or SQL) into an AST, binds names to actual schemas and fields, optimizes by pushing down filters and pruning unneeded fields early, plans a Tantivy query plus aggregation operators, and executes against the index to stream results back.
This is how Brainstore stays interactive even when fields are deeply nested, payloads are huge, and queries mix "needle-in-a-haystack" search with analytics.
Real-time reads
Together, these choices allow Brainstore to stay real-time while compaction happens in the background. Reads are not forced to wait for compaction.
When you query, Brainstore conceptually merges three sources: WAL entries that are not yet processed, entries that have been processed but not yet compacted, and fully indexed data.
This is the "real-time" portion of the engine. In practice, it is bounded by time and memory budgets so that freshness does not destroy latency for high-volume customers. For the most latency-sensitive paths, like "show me the latest traces" and "load this trace by ID," Brainstore can also use a smaller ephemeral real-time structure containing just IDs and timestamps, and fetch full payloads only when needed.
Additionally, controlling the stack like this and making it multitenant-first lets us support SQL as well as BTQL. This seems simple on the surface but rests on years of learning from building Brainstore the way we did.
Architecture as developer experience
The system-level choices above translate into a few concrete properties for developers.
Freshness. Traces and updates become visible immediately, with no "minutes behind" window. That real-time feel is essential for in-the-moment debugging, when teams need to confirm whether a change fixed the issue or made it worse.
Targeted reads. Loading a single trace is optimized to avoid broad scans, even when spans are tens of KB and traces are MB to GB in size. The goal is to make deep, single-run inspection fast and predictable.
Interactive exploration. Filtering, group-bys, and aggregates stay usable at scale because the query planner can push down filters and prune unneeded fields early. That keeps exploratory analysis responsive instead of turning every question into a slow batch job.
Text-first debugging. Full-text search across prompts and responses is a first-class query path, not an afterthought. This makes it straightforward to find the exact run or behavior you are looking for, even when the data is messy and semi-structured.
Operational simplicity. Developers do not need to reason about multiple backends or per-query routing as datasets grow. The system stays straightforward to run and straightforward to use, even under heavy production workloads.